Timestamp to Relative Time - Kibana Scripted fields
When browsing logs in Kibana, there will be a timestamp stamp field on the left for all the docs. It is difficult to read & comprehend the timestamp in the logs. It would be better if we can convert the timestamp to a human-readable relative time like 5 minutes ago, 1 hour ago, etc.
Kibana Scripted Fields
Kibana provides a feature called scripted fields to create new fields in the index pattern. We can use this feature to convert the timestamp to a relative time.
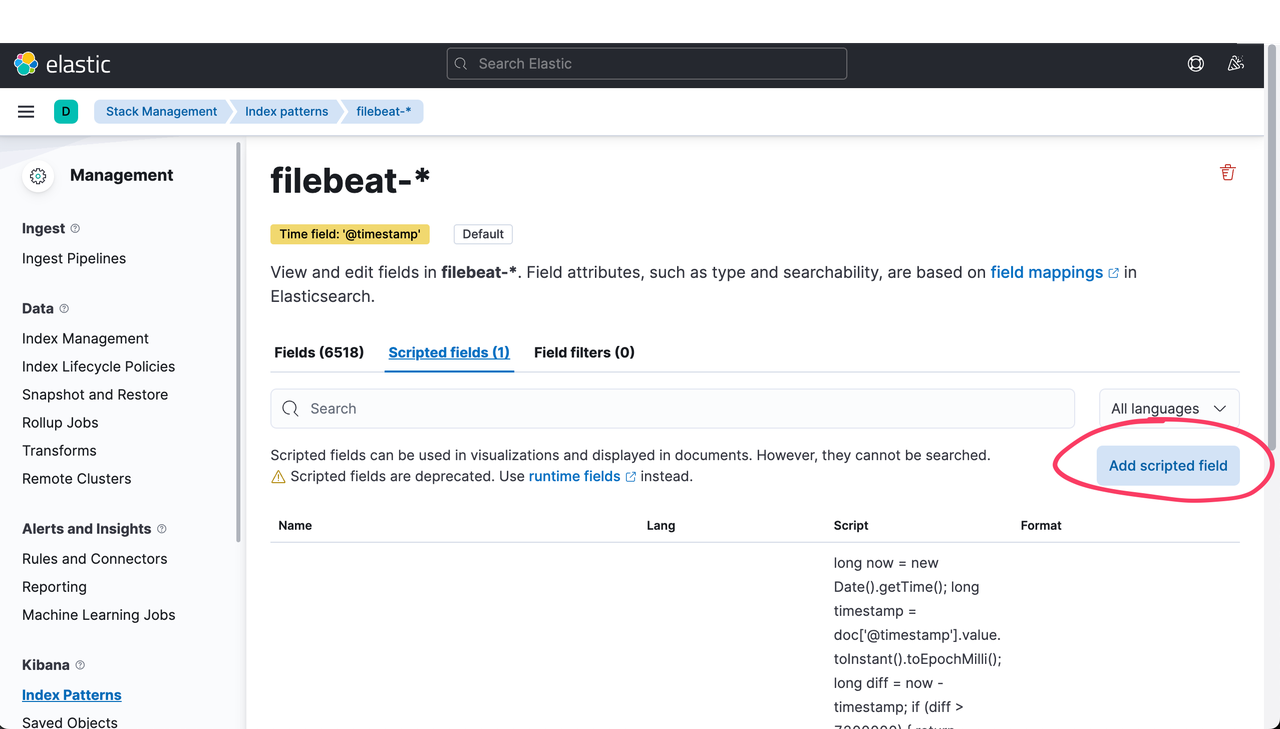
Go to Stack Management -> Index Patterns -> Create index pattern -> Select the index pattern -> Scripted fields, click on Add scripted field, add the below script.
long now = new Date().getTime(); long timestamp = doc['@timestamp'].value.toInstant().toEpochMilli(); long diff = now - timestamp; if (diff > 7200000) { return Math.round(diff / 3600000) + " hours ago"; } else if (diff > 3600000) { return Math.round(diff / 3600000) + " hour ago"; } else if (diff > 120000) { return Math.round(diff / 60000) + " minutes ago"; } else if (diff > 60000) { return (Math.round(diff / 60000) + " minute ago"); } else { return Math.round(diff / 1000) + " seconds ago"; }
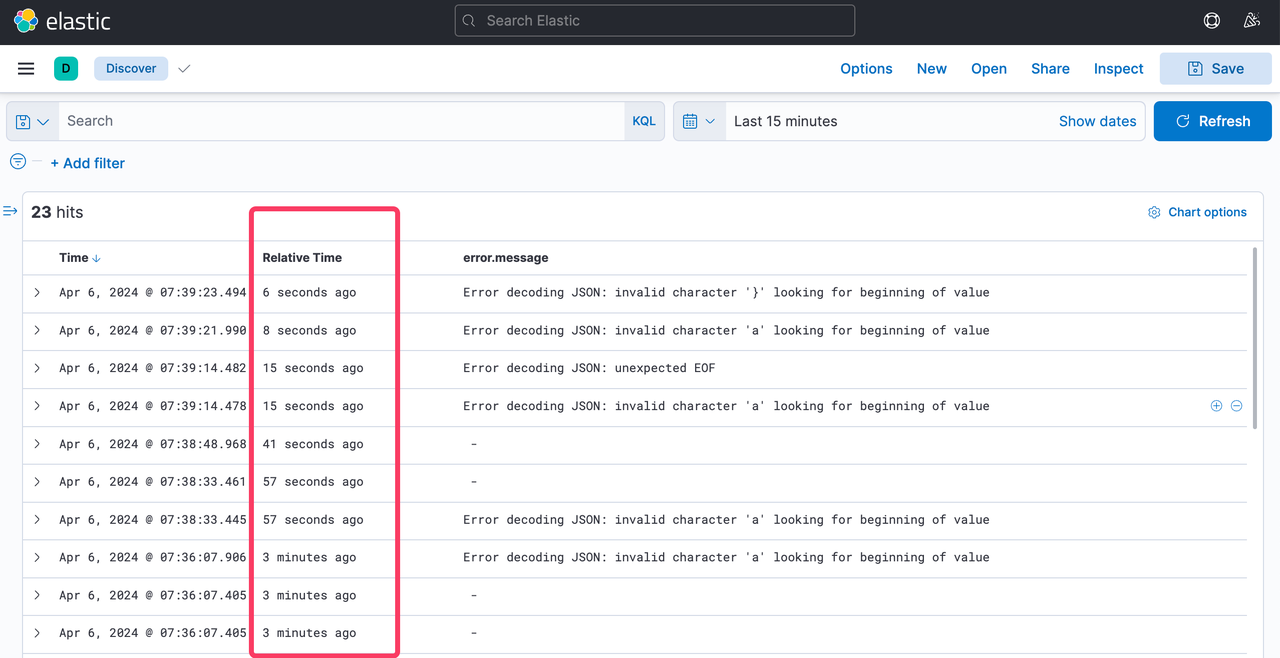
Once the field is saved, we can go back to Discover and see the new field in the logs. We can toggle the visibility of the Relative Time field to see the relative time.
Conclusion
Instead of looking at the timestamp and calculating the relative time in our head, we can use relative time in Kibana . This will make it easier to read & comprehend the logs.