In this tutorial, You will learn to install Beautiful Soup and parse any web page you like.
1. Open your terminal ( Alt + Ctrl + T ). Install Python & Soup by using these commands.
Python & Beautiful Soup Installation On Ubuntu 12.04:
1. Open your terminal ( Alt + Ctrl + T ). Install Python & Soup by using these commands.
sudo add-apt-repository ppa:fkrull/deadsnakes
sudo apt-get update
sudo apt-get install python2.7
sudo apt-get install python-bs4
Scraping A Web Page:
Lets start our programm by importing Beautiful soup. Since we are going to open a web page, we need urllib2 ( This is for Python 2, For Python 3 see urllib.request ). So import that library also. Select any url to parse. I have selected the home page of this blog and opened that page with urlopen(). Pass the web page contents of 'page' variable to beautiful soup. Lets print all the links which are present in this page.So, the final code is
from bs4 import BeautifulSoup
import urllib2
url = "https://www.goodreads.com/quotes/tag/love"
page = urllib2.urlopen(url)
soup = BeautifulSoup(page.read())
for anchor in soup.find_all('a'):
print(anchor.get('href', '/'))
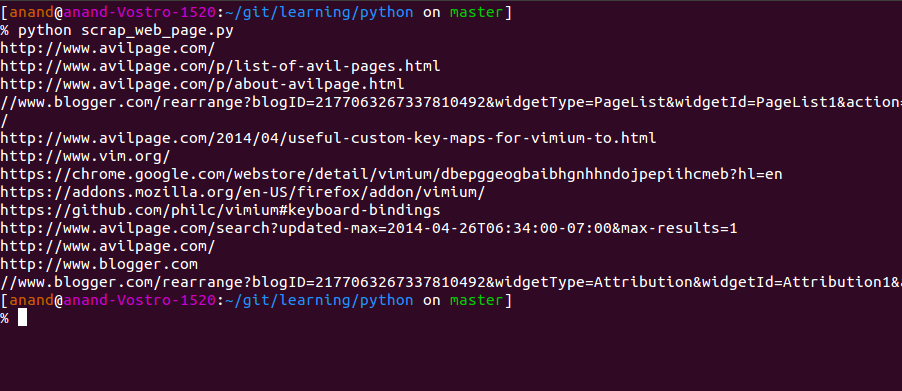
Go ahead and run this file. I have name the file as scrap_web_page.py
python scrap_web_page.py
It will produce all the links in the terminal itself. I have added a screenshot of the output I have received.
anchor.get() is just one method to get all links, you can grab any element or class or name or anything from the page. For complete details, read the documentation of Beautiful Soup.