Using LSTM-CTC For Complex Script Recognition
Most Indian languages have strong consonant-vowel structures which combine to give syllables. These syllables are written as one continuous ligature and they require complex text rendering (CTL) for type setting.
Writing OCR (Optical Character Recognition) software for CTL scripts is a challenging task as segmentation is hard. Because of this overall accuracy drops drastically.
A better approach is to use Connectionist Temporal Classification1(CTC) which can identify unsegmented sequence directly as it has a one-to-one correspondence between input samples and output labels.
Here is a sample input and output of an RNN-CTC network which takes an unsegmented sequence and outputs labels.
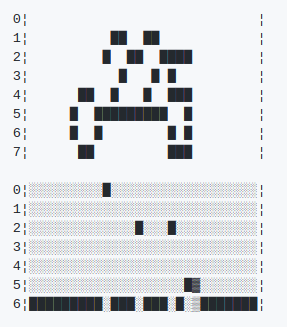
Open-source OCR software ocorpy uses BLSTM-CTC for text recognition. Tesseract started using the same in its latest(4.0) version.
I have trained a model to recognize Telugu script using Ocropy and the accuracy is ~99% which is far better when compared to OCR software without CTC which are accurate to ~70%.
Need further help with this? Feel free to send a message.

Anand Reddy Pandikunta (ChillarAnand)
Improving Health & Wealth with Technology