A short hands-on guide to get started with Apache Kafka for people who are in a hurry.
In this guide, we will learn what is Apache Kafka, how to install and run it. We will also learn how to create/modify a topic and produce/consume messages from it.
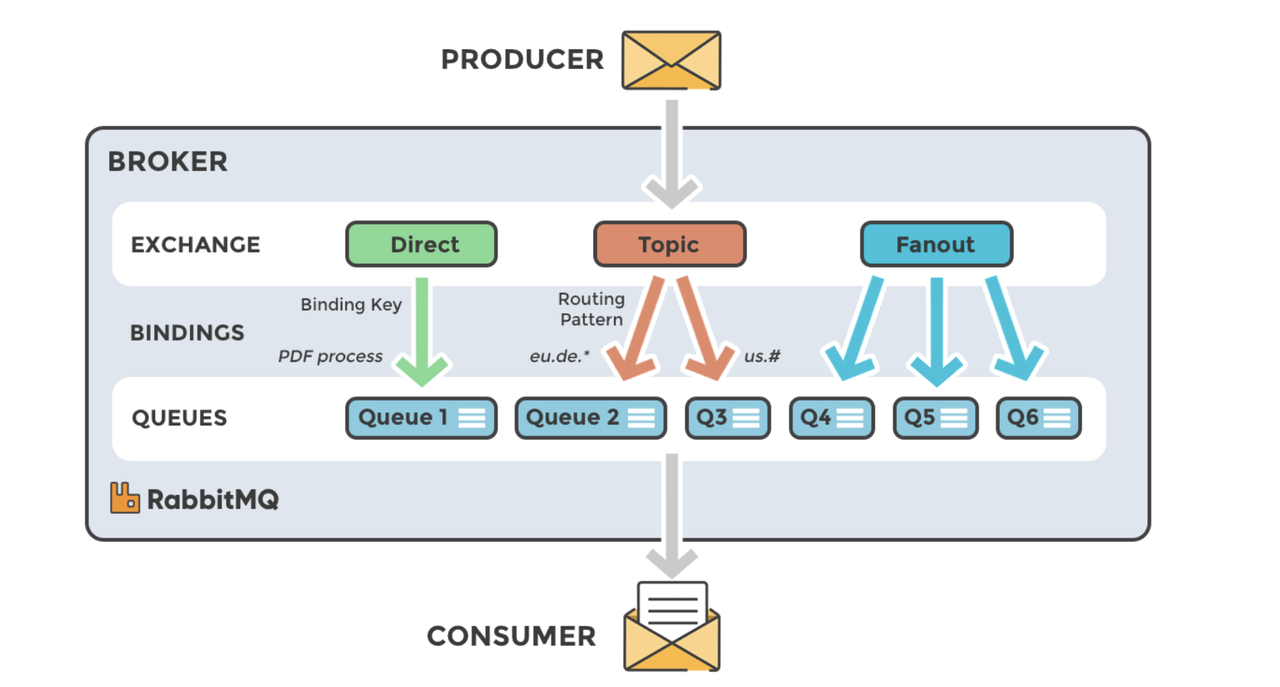
What is Apache Kafka?
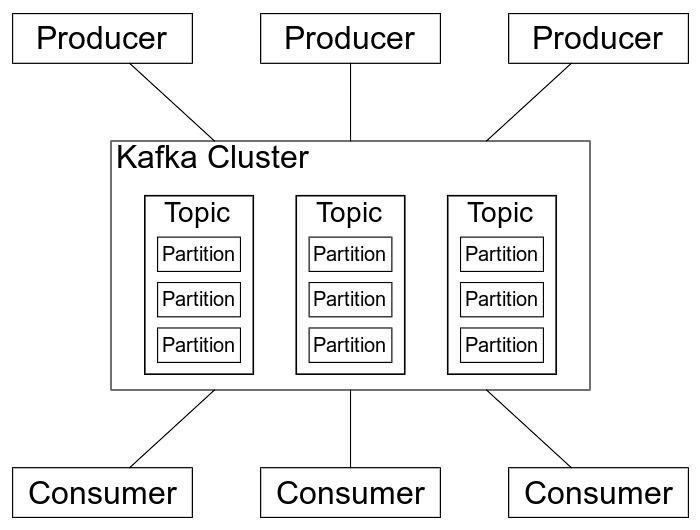
Apache Kafka is a distributed event store and streaming-processing platform. It is used to
build real-time data pipelines and streaming apps. It is horizontally scalable, fault-tolerant, and has high throughput.
Kafka Terminology
Topic: A topic is a category or feed name to which records are published/consumed. It is configured with a set of
key-value pairs called topic configuration.
Producer: A producer is a client that publishes records to the Kafka cluster. Producers write data to topics and
partitions.
Consumer: A consumer is a client that subscribes to topics and processes the records. Consumers read data from
topics and partitions.
Consumer Group: A consumer group is a group of consumers that share a common purpose. Consumer groups enable a
pool of processes to divide the work of consuming and processing records.
Broker: A broker is a server that hosts a set of topics/partitions. It receives data from producers and sends
data to consumers.
ZooKeeper: ZooKeeper is used to store the cluster configuration and the state of the cluster. All Kafka brokers
connect to ZooKeeper.
Kraft: Kraft(Apache Kafka Raft) is a consensus protocol that is used to manage the metadata of the Kafka cluster.
It is introduced to remove dependency on ZooKeeper.
Setting up Apache Kafka
We can use cp-all-in-one docker compose files to run Apache Kafka locally. This image contains all the
components of Confluent Platform including Apache Kafka, Apache Zookeeper, Confluent Schema Registry, Confluent REST
Proxy, Confluent Control Center, and others.
$ git clone https://github.com/confluentinc/cp-all-in-one
$ cd cp-all-in-one/cp-all-in-one
$ docker-compose up
Kafka CLI Tools
Kafka stores messages in topics. A topic is a category or feed name to which messages are published/consumed.
Let us create a topic called demo with kafka-topics command.
$ docker-compose exec broker kafka-topics --bootstrap-server localhost:9092 --topic demo --create
This will create a topic called demo with a single partition and a replication factor of 1. In multi-node cluster, we
can use --replication-factor, --partitions to specify the number of replicas/partitions for the topic.
$ docker-compose exec broker kafka-topics --bootstrap-server localhost:9092 --topic demo --partitions 3 --replication-factor 2 --create --if-not-exists
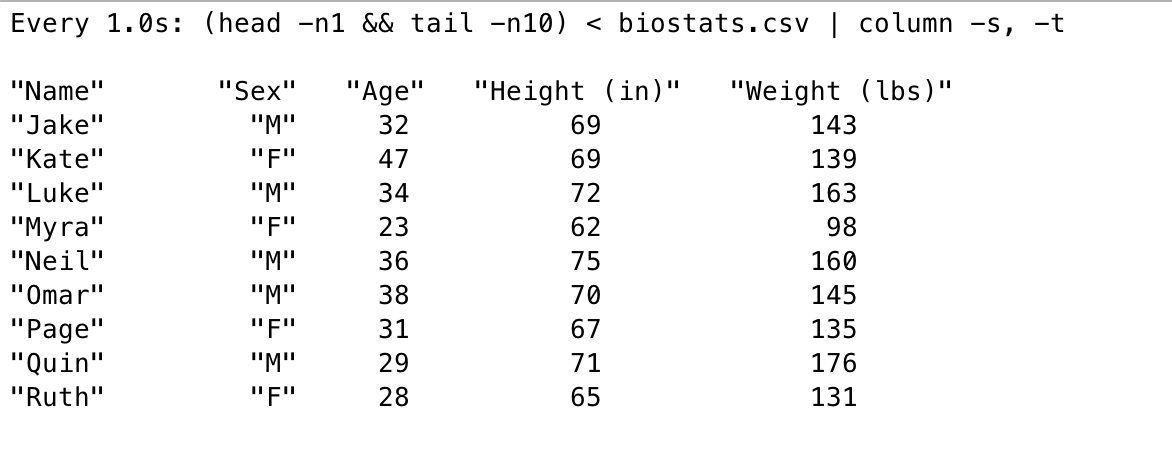
To produce messages to a topic named demo, we can use kafka-console-producer and add messages to the topic:
$ docker-compose exec broker kafka-console-producer --broker-list localhost:9092 --topic demo
>order received
>order updated
>order shipped
>order delivered
>{"status": "completed"}
To consume messages from the same topic:
$ docker-compose exec broker kafka-console-consumer --bootstrap-server localhost:9092 --topic demo --from-beginning
order received
order updated
order shipped
order delivered
{"status": "completed"}
Since we have not defined schema for the messages, Kafka will store the messages as byte arrays. We can explicitly define the schema for the messages using Confluent Schema Registry if required.
We can list all the topics in cluster using kafka-topics:
$ docker-compose exec broker kafka-topics --bootstrap-server localhost:9092 --list
default_ksql_processing_log
docker-connect-configs
docker-connect-offsets
docker-connect-status
demo
To show details of a topic:
$ docker-compose exec broker kafka-topics --bootstrap-server localhost:9092 --describe --topic demo
Topic: demo TopicId: 7CckqkXsQXCNY0MNHYRv2w PartitionCount: 1 ReplicationFactor: 1 Configs:
Topic: demo Partition: 0 Leader: 1 Replicas: 1 Isr: 1 Offline:
By default, all messages are stored in the topic for 7 days. We can change this retention period using retention.ms configuration:
$ docker-compose exec broker kafka-topics --bootstrap-server localhost:9092 --alter --topic demo --config retention.ms=10000
To see all the available consumer groups, we can use kafka-consumer-groups:
$ docker-compose exec broker kafka-consumer-groups --bootstrap-server localhost:9092 --list
Confluent Control Center
Confluent Control Center is a web UI to manage and monitor Apache Kafka.
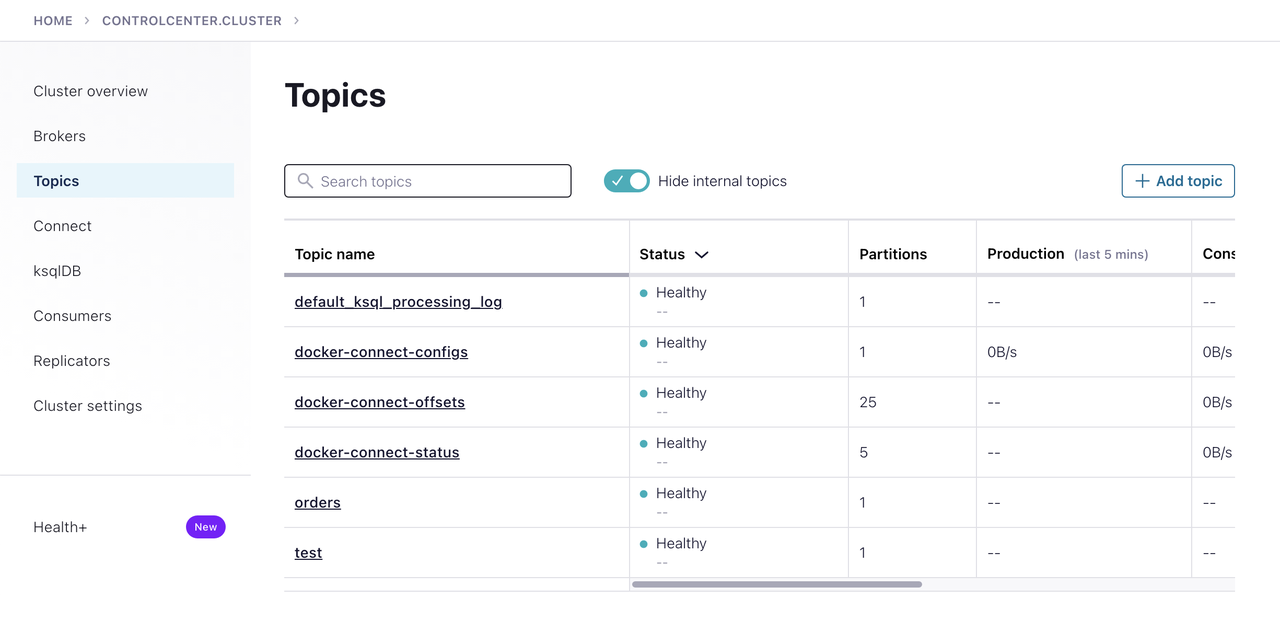
We can visit it http://localhost:9021 and access the cluster from this UI.
We can change topic configuration, view consumer groups, and monitor the cluster from this UI.
Kafka Rest Proxy
Kafka Rest Proxy is a RESTful interface to Apache Kafka. It provides a RESTful interface to produce
and consume messages, view the state of the cluster, and perform administrative actions without using the native Kafka
protocol or clients.
To list all topics in the cluster using Kafka Rest Proxy:
$ curl -X GET "http://localhost:8082/topics"
To get config of a topic:
$ curl -X GET "http://localhost:8082/topics/demo"
To produce messages to a demo topic with curl:
$ curl -X POST -H "Content-Type: application/vnd.kafka.json.v2+json" \
--data '{"records":[{"value":{"status": "completed"}}]}' \
"http://localhost:8082/topics/demo"
To consume messages from the same topic:
$ curl -X GET -H "Accept: application/vnd.kafka.json.v2+json" \
"http://localhost:8082/topics/demo"
We can dynamically configure Kafka cluster settings as well.
To change log level of various components of Kafka cluster using Kafka Rest Proxy.
$ curl -X POST -H "Content-Type: application/vnd.kafka.v2+json" \
--data '{"log4j.logger.kafka.server":"DEBUG"}' \
"http://localhost:8082/config"
We can update the log level of various components of Kafka cluster and check the logs.
Kafka Connect
Kafka Connect is a framework to stream data between Apache Kafka and other systems. It is used to import/export data from/to Kafka.
Lets use the DataGenConnector to generate random data and write it to a topic.
curl --location 'http://localhost:8083/connectors' \
--header 'Content-Type: application/json' \
--data '{
"name": "datagen-pageviews",
"config": {
"connector.class": "io.confluent.kafka.connect.datagen.DatagenConnector",
"kafka.topic": "datagen-pageviews",
"quickstart": "pageviews",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": "false",
"max.interval": 100,
"iterations": 10000000,
"tasks.max": "1"
}
}
'
This will create a connector called datagen-pageviews which will generate random data and write it to a topic called datagen-pageviews.
KsqlDB
KsqlDB is a streaming SQL engine for Apache Kafka. It provides a SQL interface to query, transform, and analyze data in Kafka.
Lets create a stream called pageviews from the topic datagen-pageviews:
$ curl -X "POST" "http://localhost:8088/ksql" \
-H "Content-Type: application/vnd.ksql.v1+json; charset=utf-8" \
-d $'{
"ksql": "CREATE STREAM pageviews (viewtime BIGINT, userid VARCHAR, pageid VARCHAR) WITH (KAFKA_TOPIC=\'datagen-pageviews\', VALUE_FORMAT=\'JSON\');",
"streamsProperties": {}
}'
We can create a table to generate viewcount per pageid:
$ curl -X "POST" "http://localhost:8088/ksql" \
-H "Content-Type: application/vnd.ksql.v1+json; charset=utf-8" \
-d $'{
"ksql": "CREATE TABLE pageviews_count AS
SELECT
pageid,
COUNT(*) AS page_views_count
FROM pageviews_stream
GROUP BY pageid
EMIT CHANGES;
",
"streamsProperties": {}
}'
We can query the table to get the viewcount per pageid:
$ curl -X "POST" "http://localhost:8088/ksql" \
-H "Content-Type: application/vnd.ksql.v1+json; charset=utf-8" \
-d $'{
"ksql": "SELECT * FROM pageviews_count EMIT CHANGES;",
"streamsProperties": {}
}'
Conclusion
In this article, we have seen how to install Apache Kafka locally using Docker. We have also seen how to produce and consume messages using Kafka console commands and Kafka Rest Proxy.